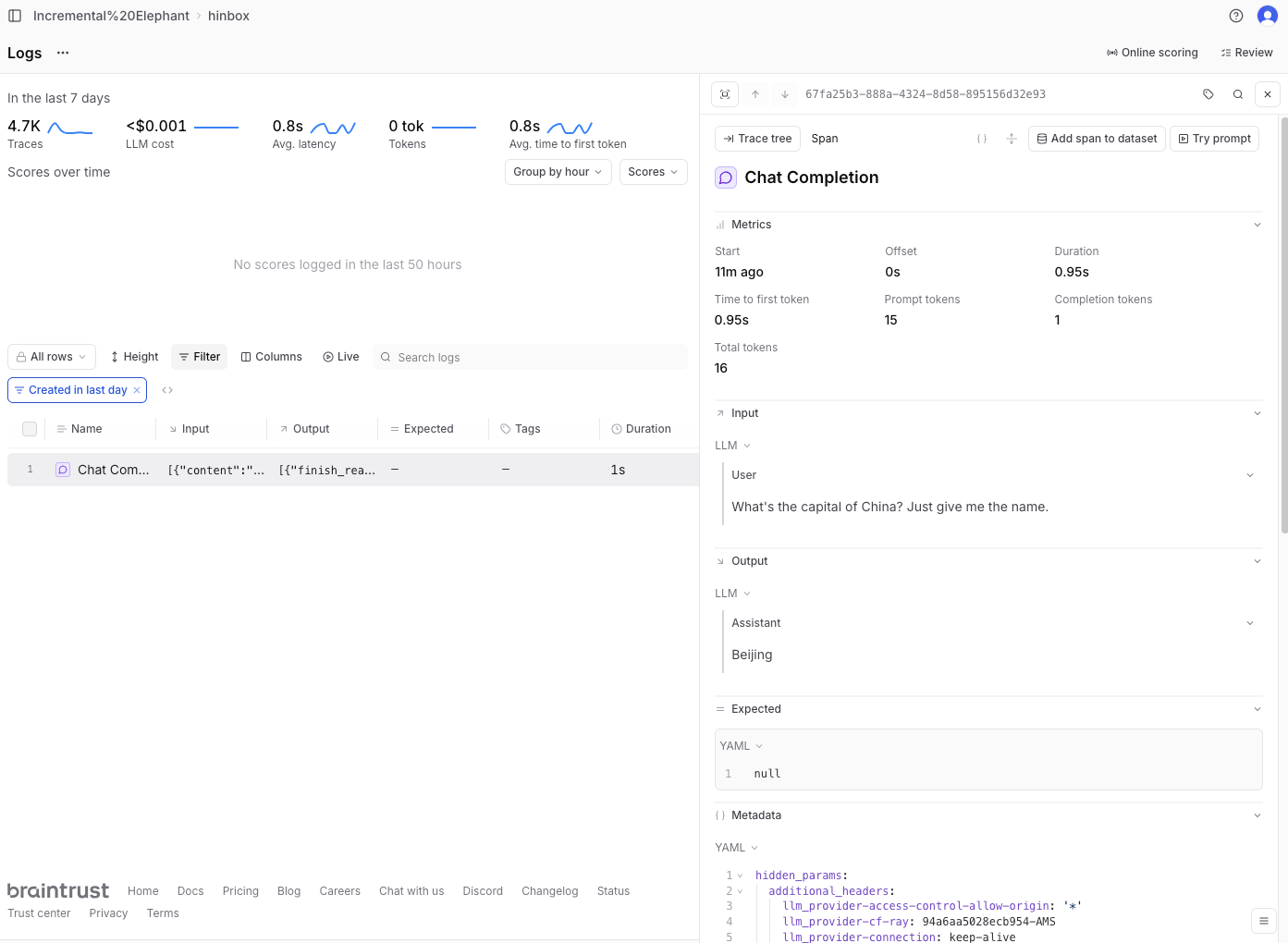
Testing out instrumenting LLM tracing for litellm with Braintrust and Langfuse
Third time’s a charm: setting up instrumentation with Braintrust, Langfuse and litellm. Braintrust ended up not being as ergonomic as Langfuse so I switch over midway.
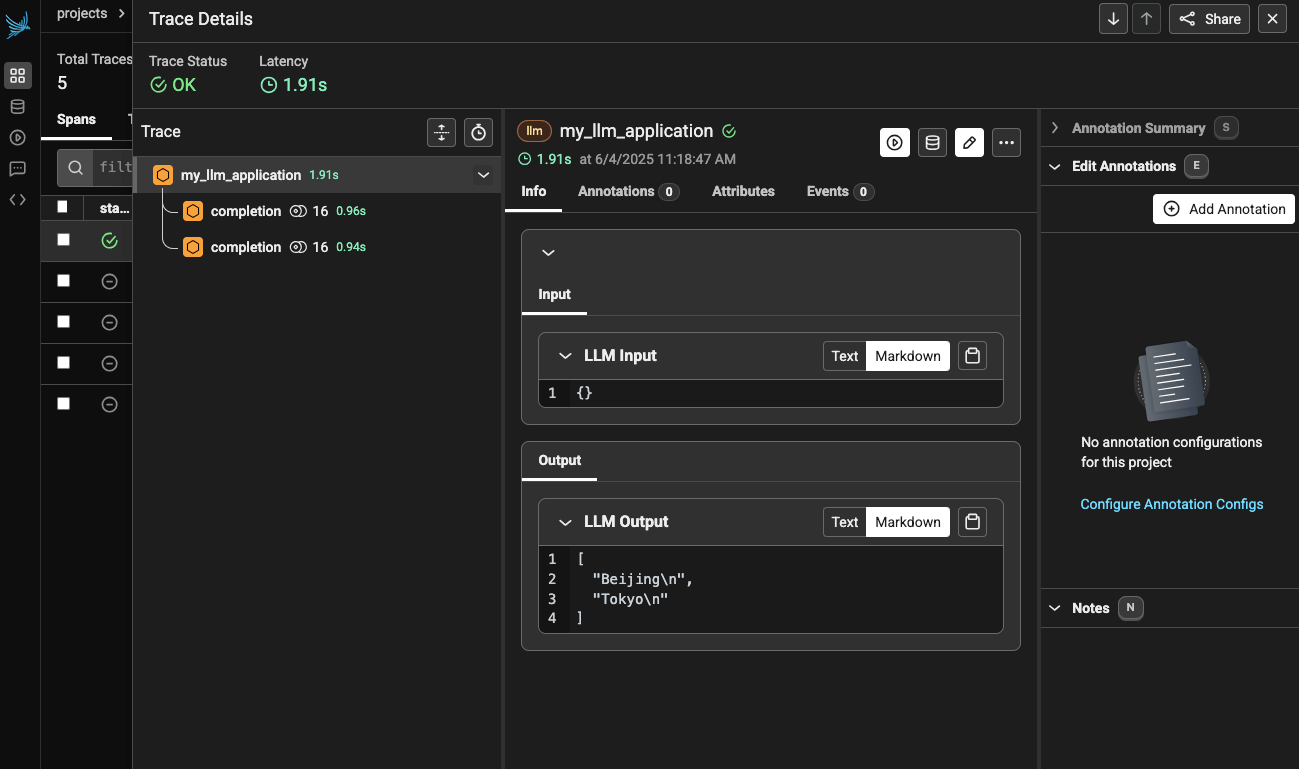
Trying to instrument an agentic app with Arize Phoenix and litellm
Trying to get Phoenix to work with litellm to instrument my LLM calls, grouping spans together as traces.
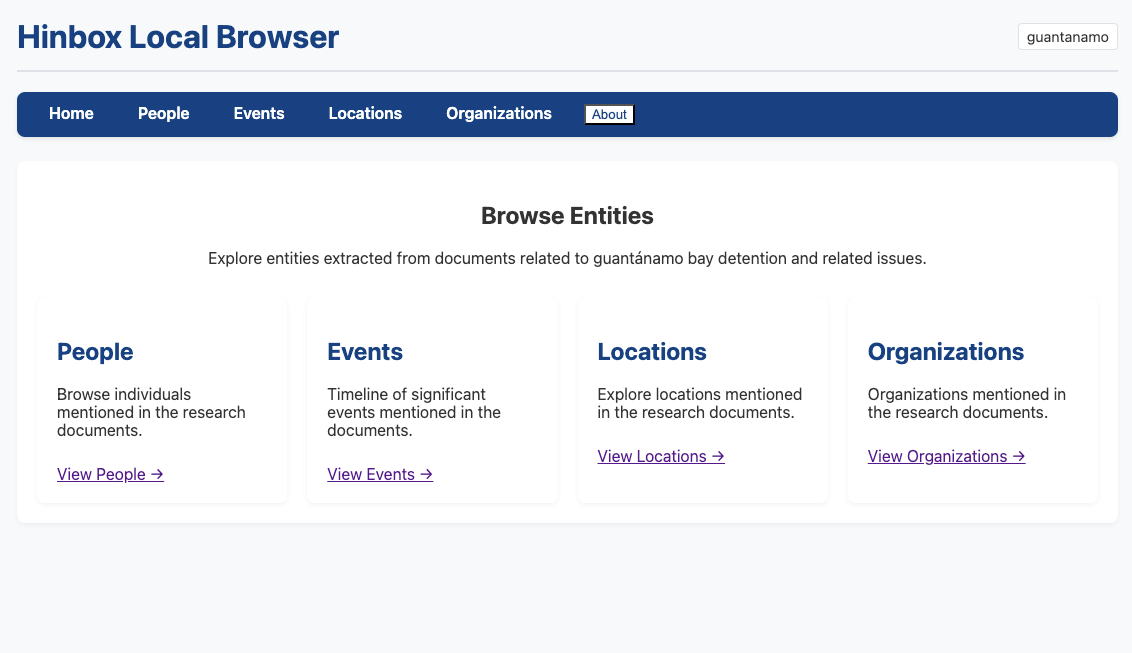
Building hinbox: An agentic research tool for historical document analysis
Lessons learned from working on an entity extraction system for historical research that automatically processes documents to create structured knowledge databases, developed as a practical testbed for systematic AI evaluation techniques.
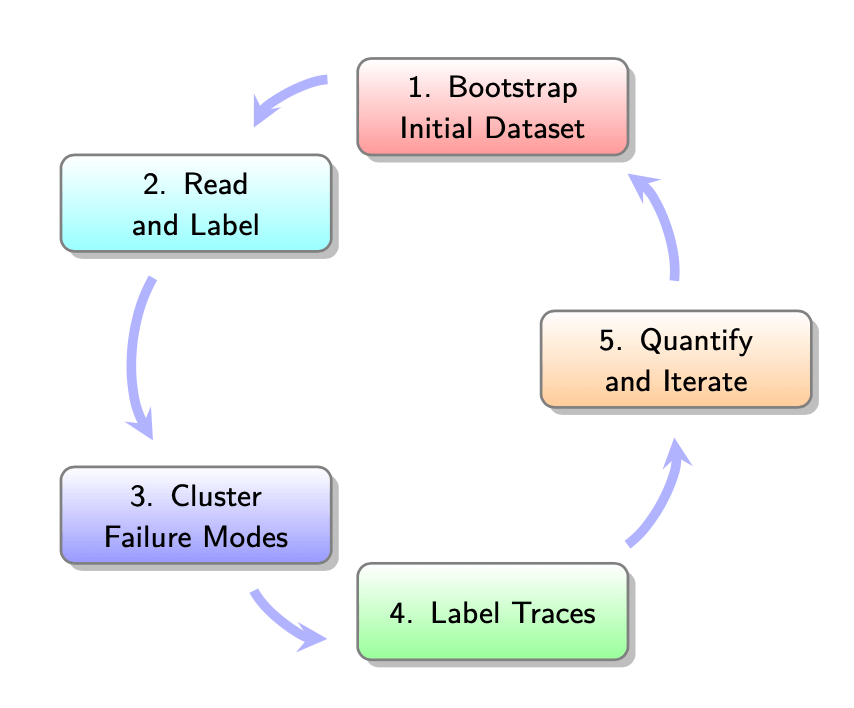

How to think about evals
Key insights from the first session of the Hamel/Shreya AI Evals course, focusing on a ‘three gulfs’ mental model (specification, generalisation, and comprehension) for LLM application development and the importance of systematic evaluation and improvement processes.
Learnings from a week of building with local LLMs
Insights from a week of building an LLM-based knowledge database, highlighting experiences with local models, prompt engineering patterns, development tools like Ollama and RepoPrompt, and software engineering principles that enhance AI-assisted development workflows.

Building an MCP Server for Beeminder: Connecting AI Assistants to Personal Data
I built a Model Context Protocol (MCP) server for Beeminder to connect AI assistants with my personal goal tracking data. Here’s how I implemented this integration using Claude Desktop, what I learned about MCP development.

Tinbox: an LLM-based document translation tool
Explores an open-source tool I built that tackles the challenges of large-scale document translation using LLMs. Born from my experience as both a historian working with Afghan primary sources and a developer, it offers innovative solutions to common translation problems through smart chunking algorithms and local model support, making multilingual content more accessible for researchers and developers alike.

Starting the Hugging Face Agents course
Some observations on completing unit one of the new course hosted by Hugging Face.
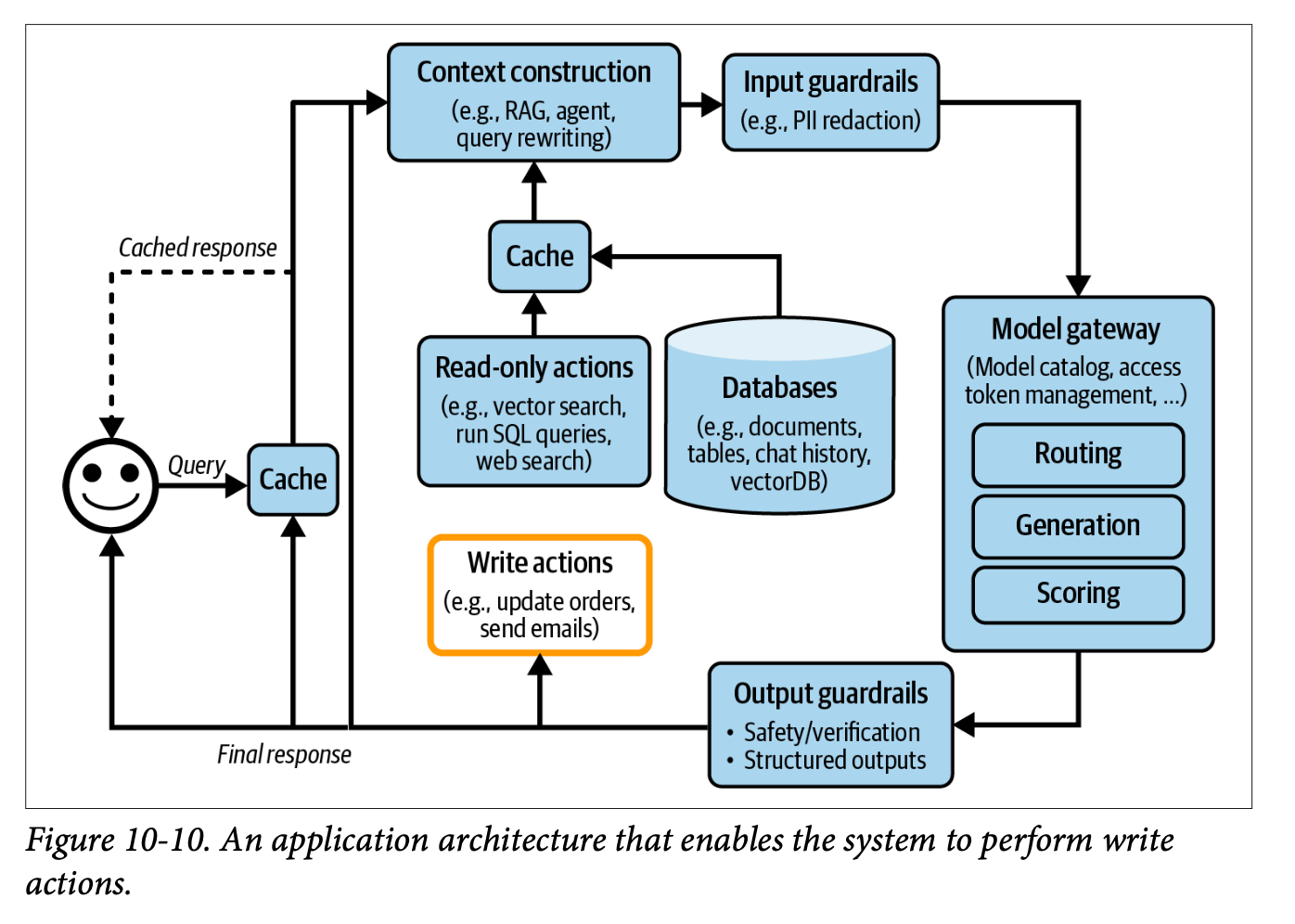
AI Engineering Architecture and User Feedback
My notes on chapter 10 of Chip Huyen’s ‘AI Engineering’, an exploration of modern AI system architecture patterns and user feedback mechanisms, covering the evolution from simple API integrations to complex agent-based systems, including practical implementations of RAG, guardrails, caching strategies, and systematic approaches to gathering and utilizing user feedback for continuous improvement.

Notes on ‘AI Engineering’ chapter 9: Inference Optimisation
Chapter 9 is a guide to ML inference optimization covering compute and memory bottlenecks, performance metrics, and practical implementation strategies. This technical summary explores model-level, hardware-level, and service-level optimizations, with detailed explanations of batching strategies, parallelism approaches, and attention mechanisms - essential knowledge for ML engineers working to reduce inference costs and improve system performance.
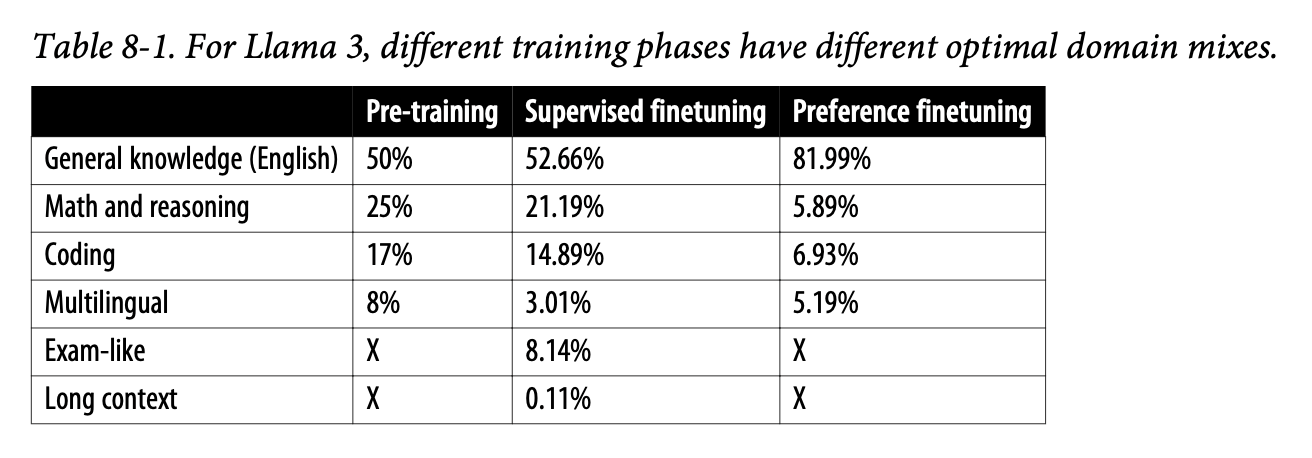
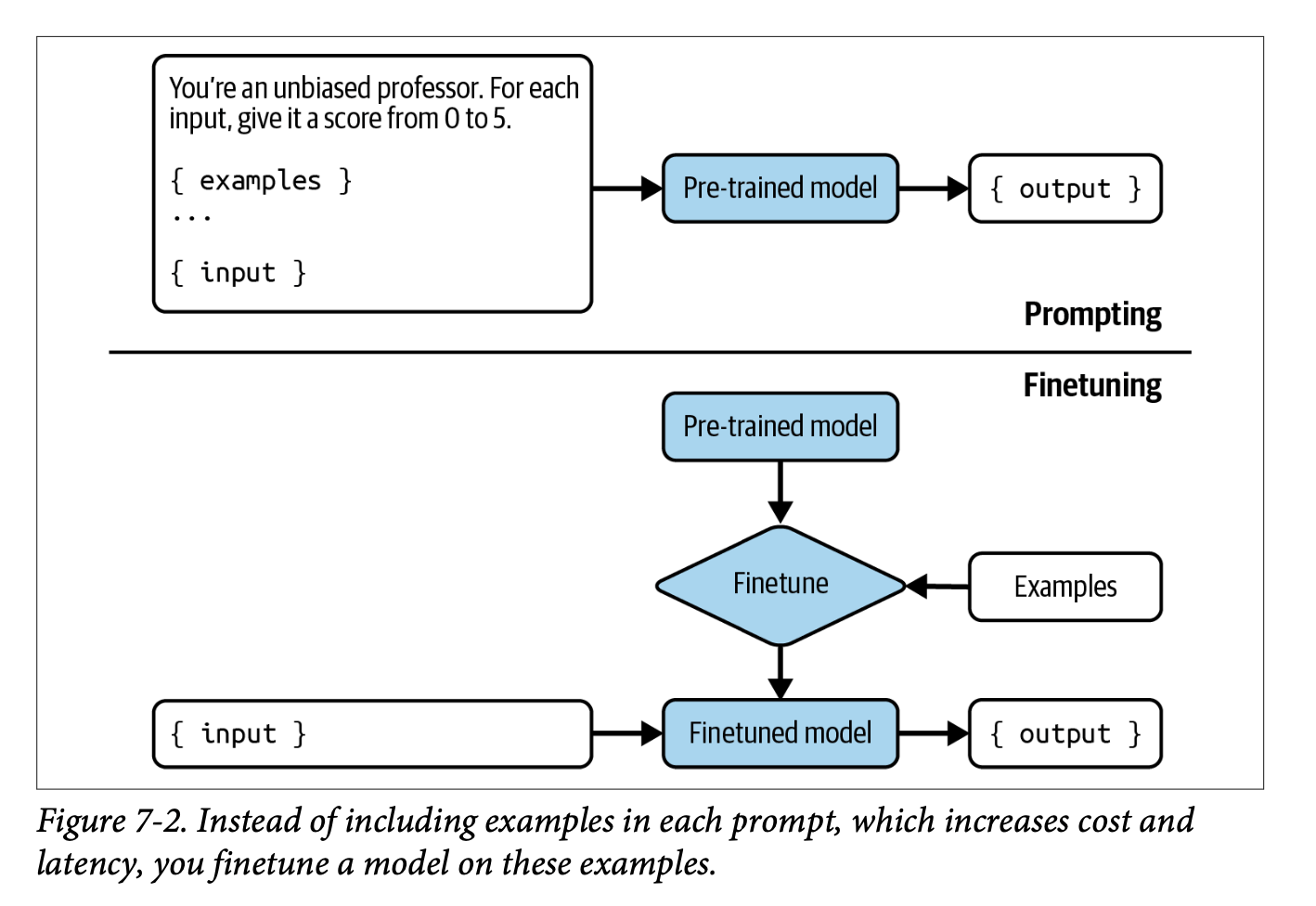
Notes on ‘AI Engineering’ (Chip Huyen) chapter 7: Finetuning
Explores when and how to implement finetuning effectively, looking at key technical aspects like memory considerations and PEFT, while emphasising fine-tuning as a last-resort approach after simpler solutions like prompt engineering and RAG have been exhausted.
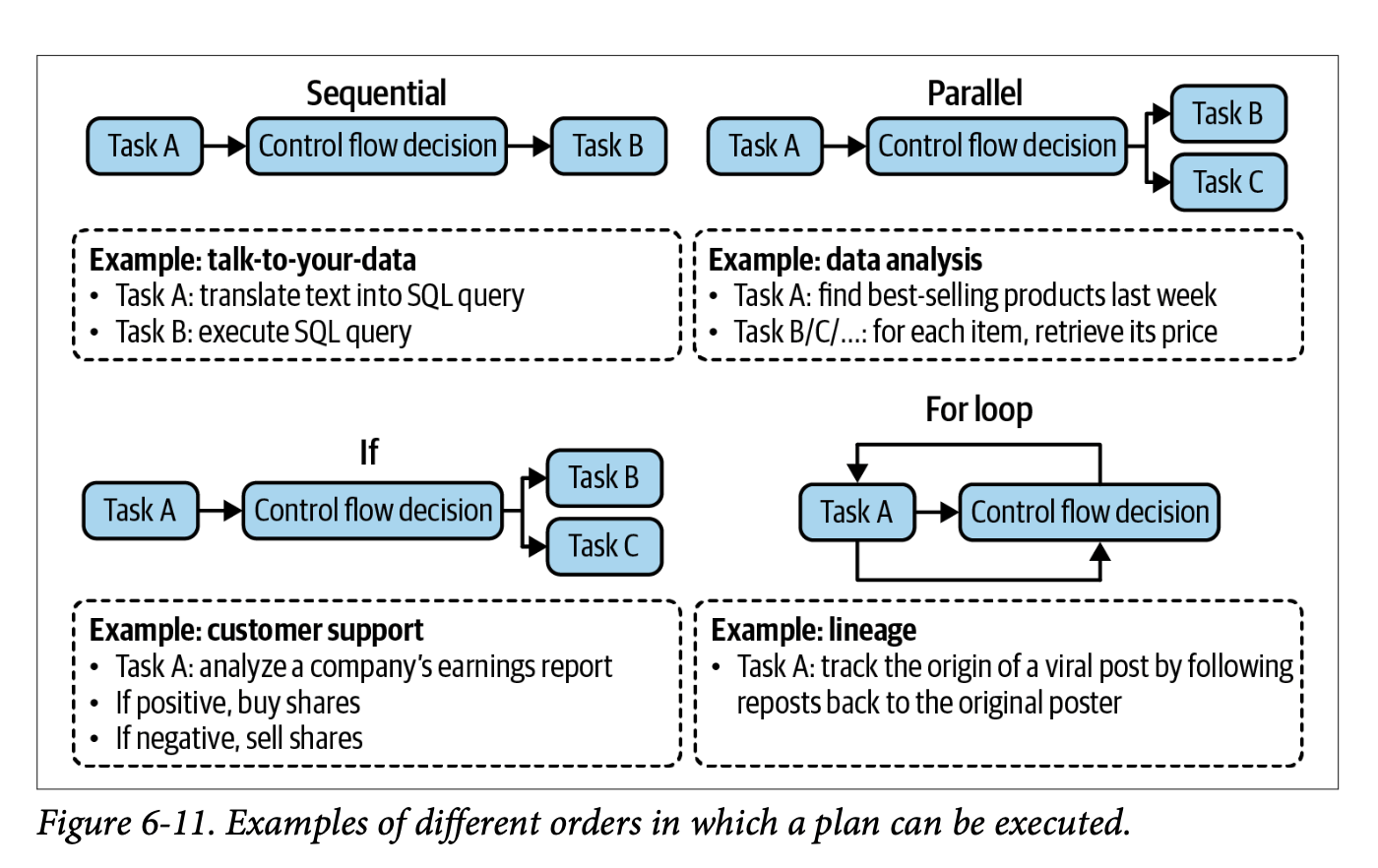
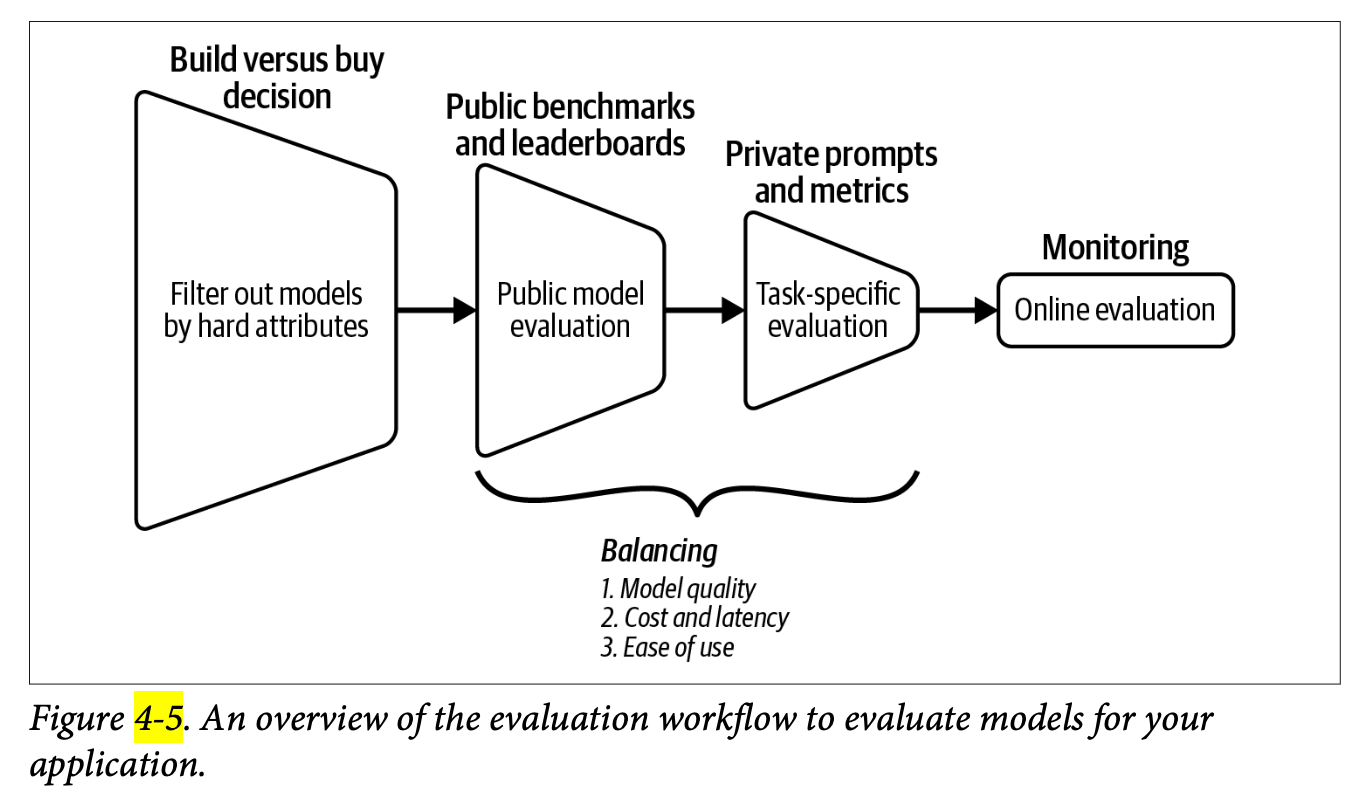
Notes on ‘AI Engineering’ (Chip Huyen) chapter 4
A comprehensive guide to AI system evaluation, synthesising Chapter 4 of Chip Huyen’s ‘AI Engineering.’ These notes detail practical frameworks for assessing AI models, covering evaluation criteria, model selection strategies, and pipeline implementation, while maintaining a balanced perspective between academic rigour and real-world application needs.

Notes on ‘AI Engineering’ (Chip Huyen) chapter 1
A detailed analysis of Chapter 1 from Chip Huyen’s ‘AI Engineering’ book, covering the transition from ML Engineering to AI Engineering, the three-layer AI stack, and modern development paradigms. Includes insights from a study group discussion on enterprise adoption challenges and emerging evaluation techniques.
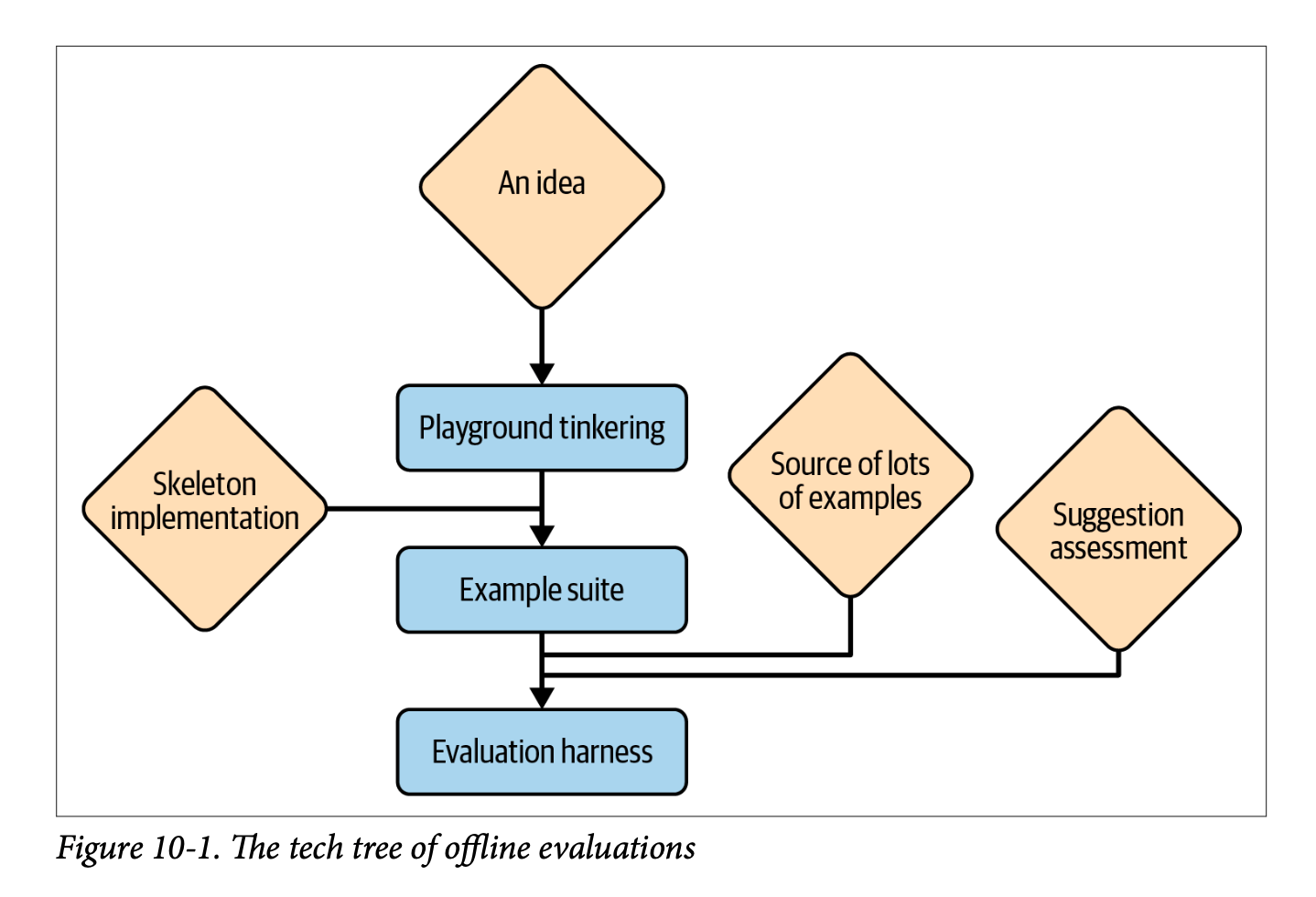
Final notes on ‘Prompt Engineering for LLMs’
Detailed notes covering Chapters 10 and 11 of ‘Prompt Engineering for LLMs’ by Berryman and Ziegler, focusing on LLM application evaluation and future trends. Chapter 10 explores comprehensive testing frameworks including offline example suites and online AB testing, while Chapter 11 discusses multimodality, user interfaces, and core principles for effective prompt engineering. Includes personal insights on the book’s emphasis on completion models versus chat models.
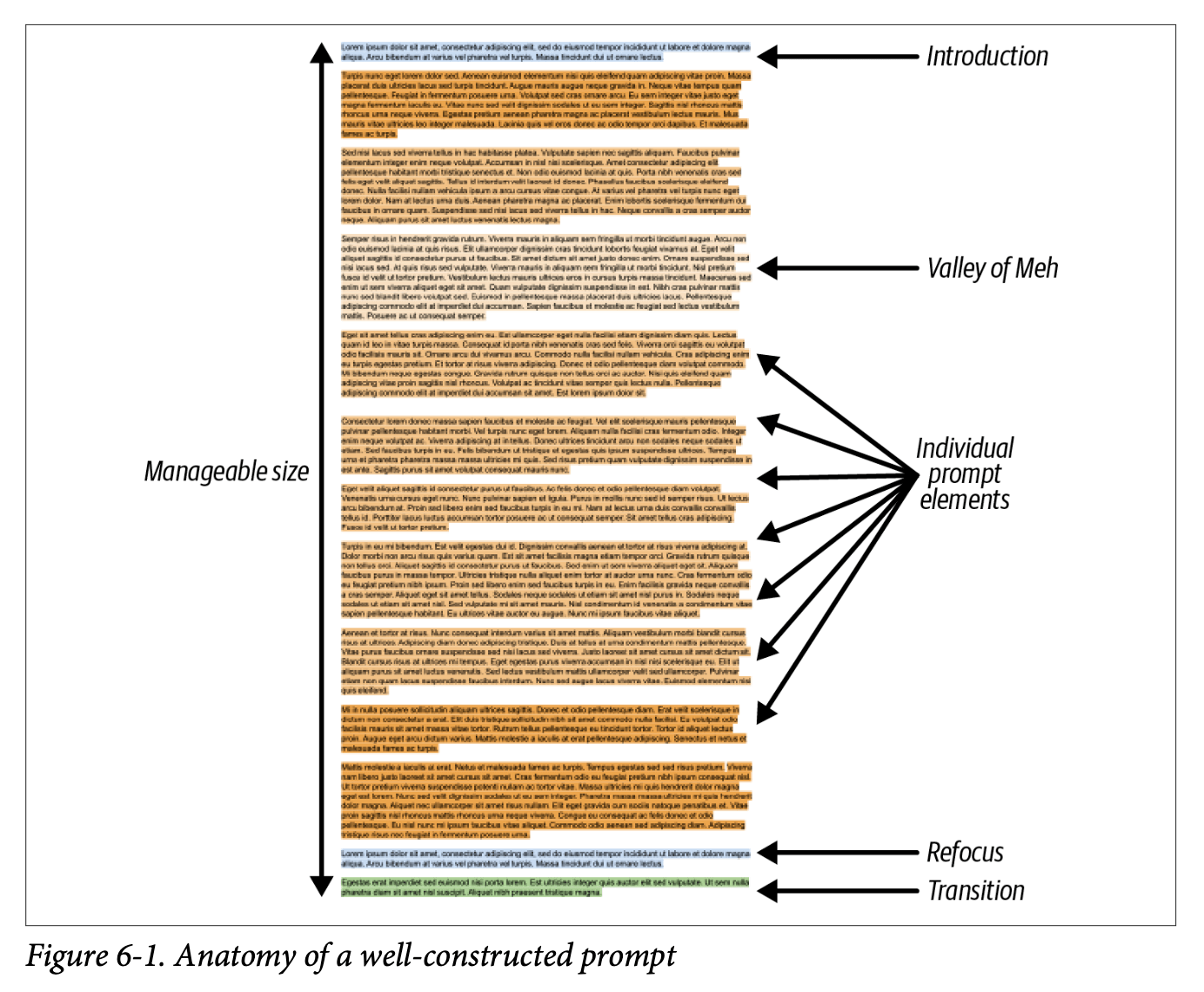
Assembling the Prompt: Notes on ‘Prompt Engineering for LLMs’ ch 6
A detailed breakdown of Chapter 6 from ‘Prompt Engineering for LLMs,’ examining prompt structure, document types, and optimization strategies for effective prompt engineering, with practical tips on information positioning and context selection within prompts.
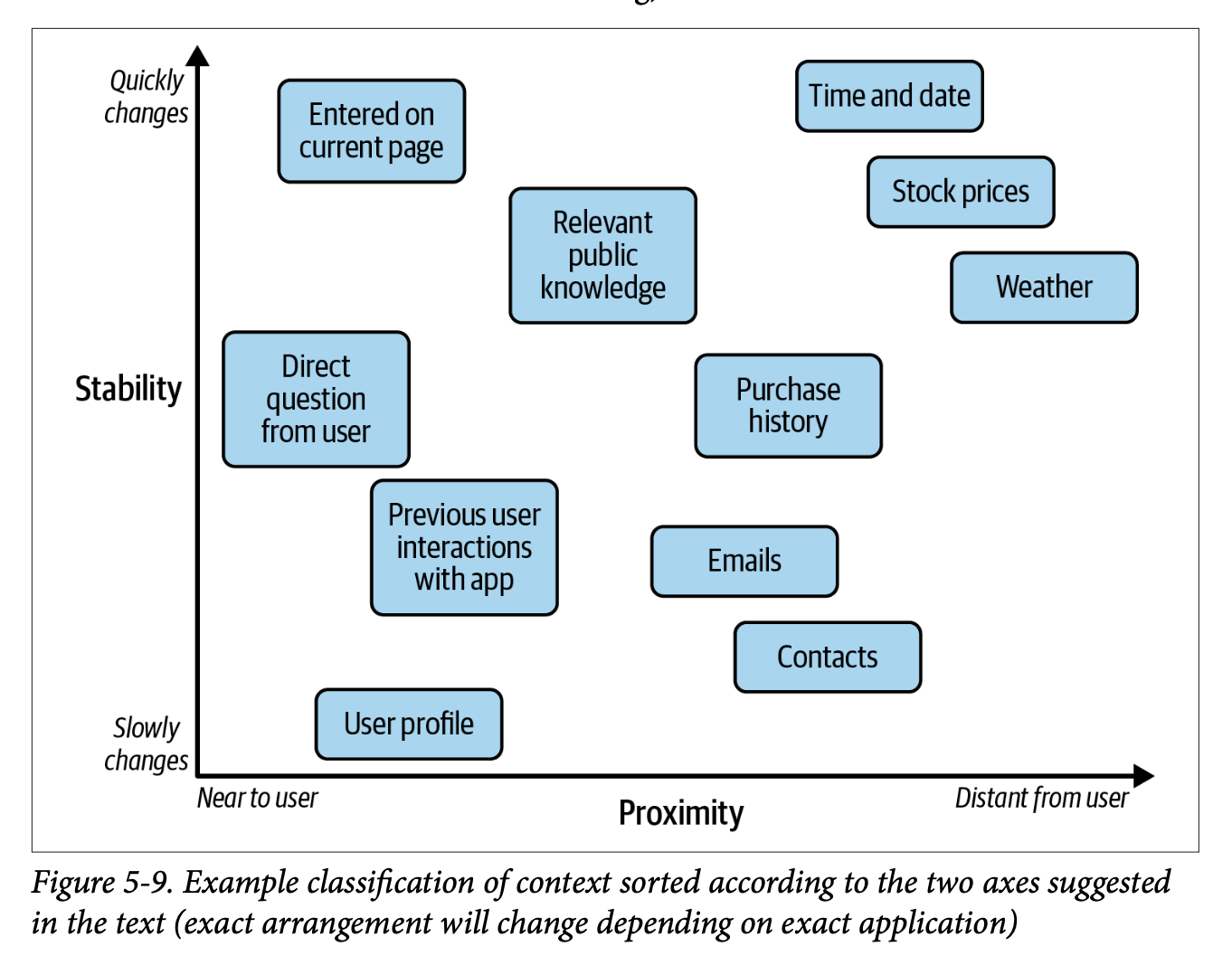
Prompt Content: Notes on ‘Prompt Engineering for LLMs’ ch 5
Chapter 5 of ‘Prompt Engineering for LLMs’ explores static content (fixed instructions and few-shot examples) versus dynamic content (runtime-assembled context like RAG) in prompts, offering tactical guidance on implementation choices, tradeoffs, and potential pitfalls while emphasising practical examples throughout.
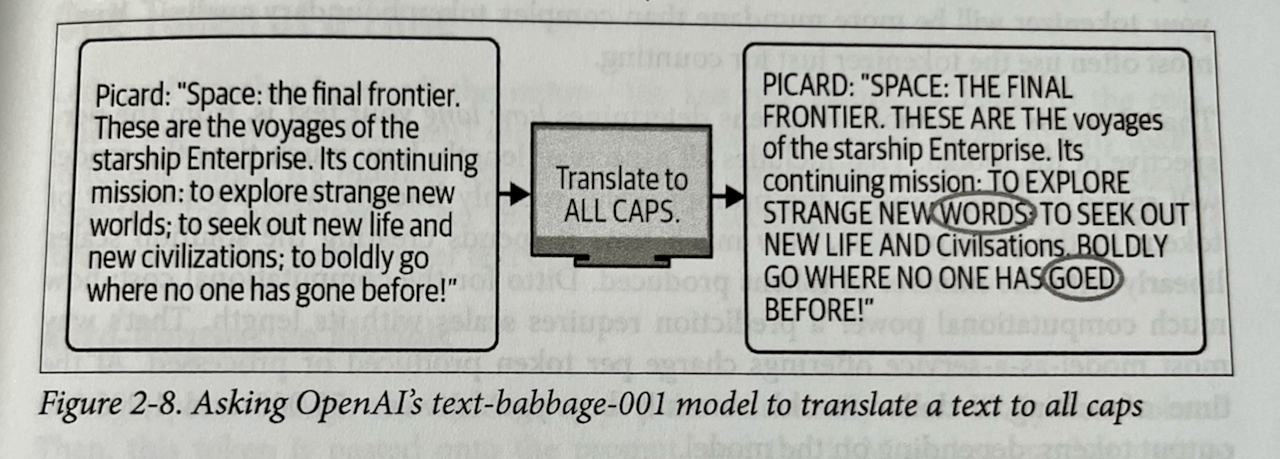
Starting to read Prompt Engineering for LLMs
Summary notes from the first two chapters of ‘Prompt Engineering for LLMs’.
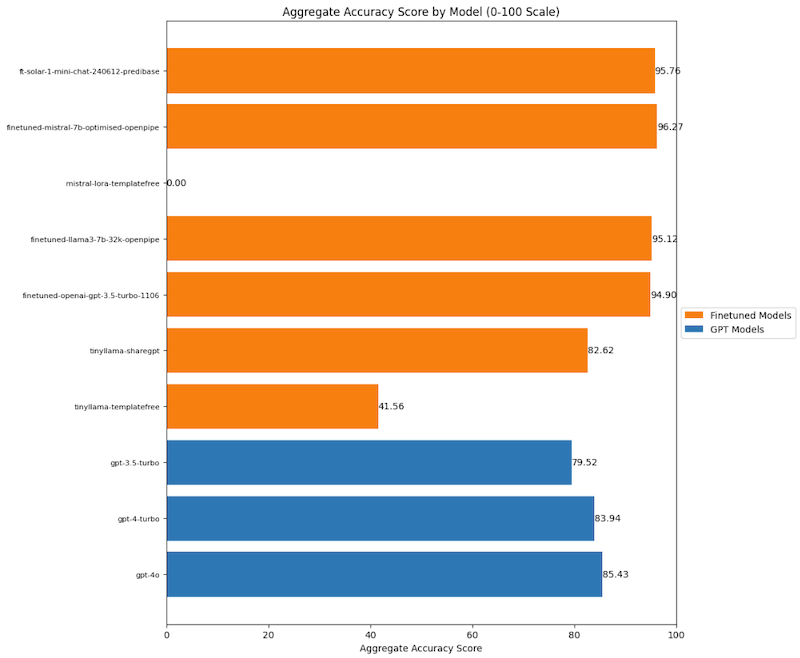
My finetuned models beat OpenAI’s GPT-4
Finetunes of Mistral, Llama3 and Solar LLMs are more accurate for my test data than OpenAI’s models.
How to think about creating a dataset for LLM finetuning evaluation
I summarise the kinds of evaluations that are needed for a structured data generation task.

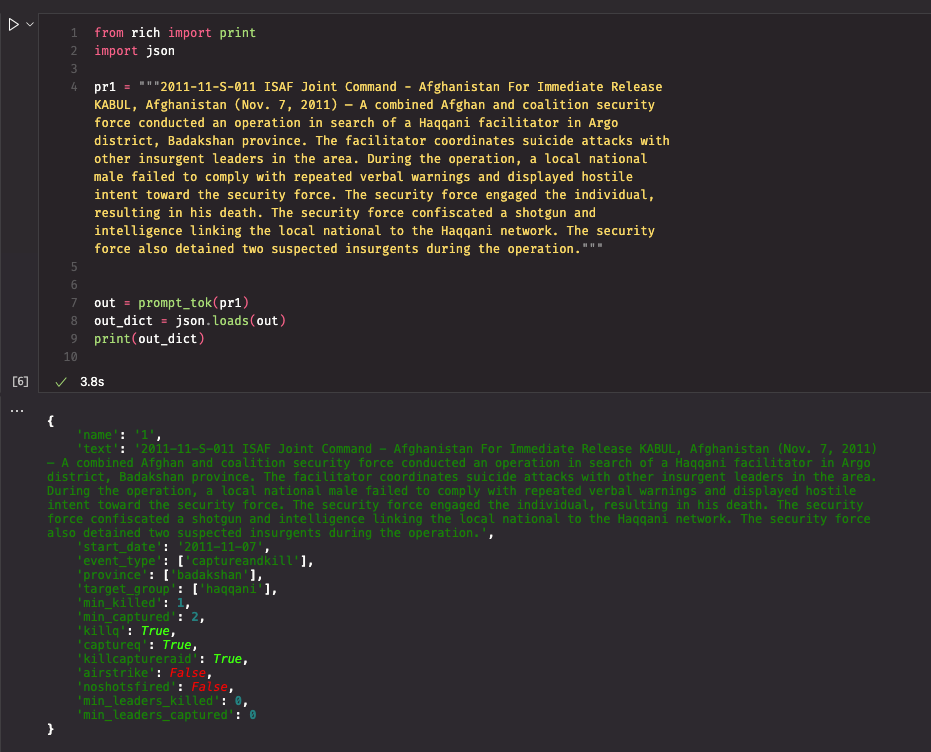

Evaluating the Baseline Performance of GPT-4-Turbo for Structured Data Extraction
I evaluated the baseline performance of OpenAI’s GPT-4-Turbo on the ISAF Press Release dataset.

Structured Data Extraction for ISAF Press Releases with Instructor
I used Instructor to understand how well LLMs are at extracting data from the ISAF Press Releases dataset. They did pretty well, but not across the board.

Introducing the Afghanwire Dataset: A Unique Collection of Translated Afghan Media Articles from 2006-2009
I’m publishing a unique new dataset of Afghan newspaper and magazine articles from the 2006-2009 period. This collection of over 7990 articles were originally translated from Dari and Pashto and published by Afghanwire, a media monitoring organisation that I co-founded and ran in Kabul at the time.

Publishing the ISAF Press Releases dataset
I published a dataset from my previous work as a researcher in Afghanistan. It consists of press releases about military operations as well as full annotations showcasing information extracted from those press releases. It has value as a historical artifact but potentially could be used as an LLM evaluation task as well.

Automating database backups with Tarsnap
I added a cronjob to automate database backups for my MathsPrompt questions.

Building MathsPrompt: a tool to help me review and practice problems for my degree
I built a tool to help me practice the parts of mathematics that I find hardest. I also have been reading some books about Rust and I also wanted to play around with that so used it for the server / backend.

Terraform Input Variables
All the ways you can set input and local variables when using Terraform.

Tokenizer Links
Some links and random observations relating to tokenisation as gathered over the past week.
Tokenizing Balochi with HuggingFace’s Tokenizer and FastAI/Spacy
I explore language tokenization using FastAI, Spacy, and Huggingface Tokenizers, with a special focus on the less-represented Balochi language. I share the challenges I faced due to language-specific limitations, my initiative to expand language metadata, and my plans to assess and enhance tokenization efficiency.


The Risks of Language Models in Minority Languages
The dual-edged nature of developing a language model for the Balochi language, weighing potential benefits like improved communication, accessibility, and language preservation against serious risks such as misuse by state actors for surveillance and power consolidation, and the unintentional promotion of linguistic monoculture.

Low-resource language models: making a start with Balochi
The Balochi language is underrepresented in NLP. I’m interested in contributing to the field by building a language model for Balochi from scratch and contributing training resources and datasets along the way.


Exponents and Logarithms: a MU123 review
I delved into exponents and logarithms in my Open University Maths degree, discovering their practical applications and connections to concepts like Euler’s number. Gaining a deeper understanding, I enjoyed manipulating symbols and working with these fascinating mathematical tools.

Terraform for the Uninitiated: Demystifying Your First Codebase
Learn the essentials of working with Terraform as a beginner, including basic commands like init, plan, apply, and destroy. Gain insights into code structure, variables, outputs, and providers while exploring a new codebase.

How to remove a commit (or two) from your git branch
Instructions how to remove a commit from your git logs.

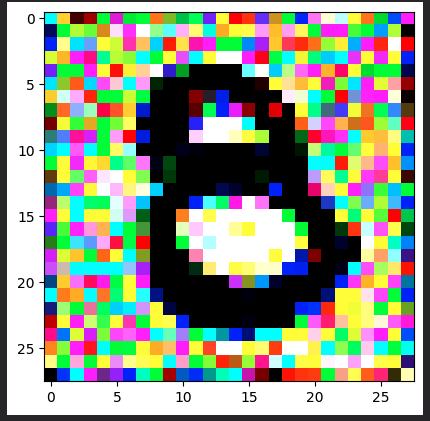

Tricking my digits classifier with diffusion
I accidentally built a way to adversarially generate handwritten images that seem to be of the number eight, but aren’t. This blog showcases an experiment I made around the core process going on in the generative diffusion process.



Deep learning tricks all the way down, with a bit of mathematics for good measure
Notes and reflections based on the first lesson (aka ‘lesson 9’) of the FastAI Part II course. This covers the fundamentals of Stable Diffusion, how it works and some core concepts or techniques.


Storing Bytes: what data serialisation is and why you need it for machine learning
I explain the basics around data serialisation and deserialisation, why it’s a commonly-encountered topic, and showcase where I had to implement some custom logic to serialise custom Python objects used in a computer vision project.
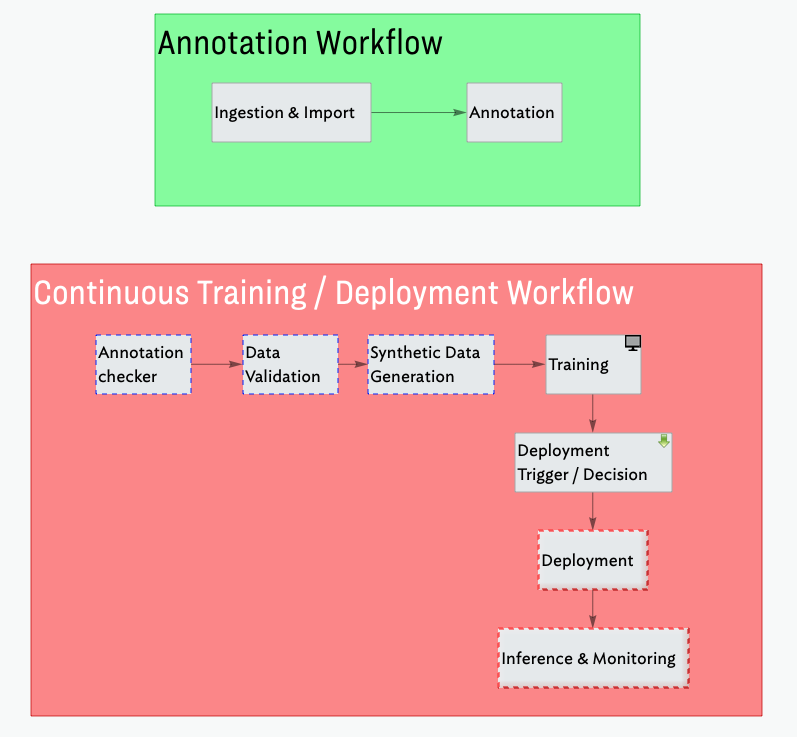
It takes a tribe: how I’m thinking about putting my object detection model into production
There are many pieces involved when deploying a model. This post covers the ones that relate to my object detection model and I explain how I’m going to put together the pipelines that will drive a continuous training loop once it’s all up.

More Data, More Problems: Using DVC to handle data versioning for a computer vision problem
I show you why you probably want to be versioning your data alongside your code. I introduce the basic functionality of DVC, the industry-standard tool for data versioning. I also explain specifically how I’m using DVC for my computer vision project.
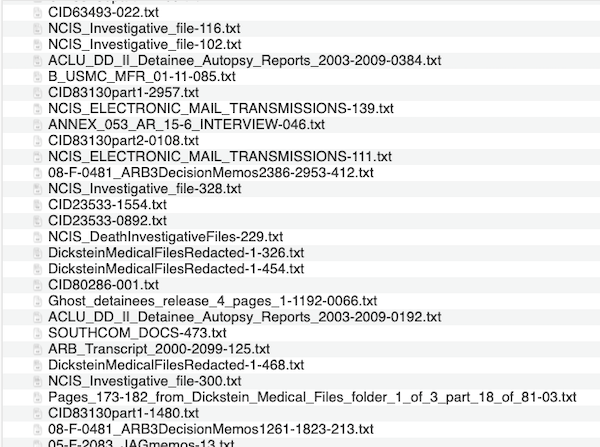
Redaction Image Classifier: NLP Edition
I train an NLP model to see how well it does at predicting whether an OCRed text contains a redaction or not. I run into a bunch of issues when training, leading me to conclude that training NLP models is more complicated than I’d at first suspected.
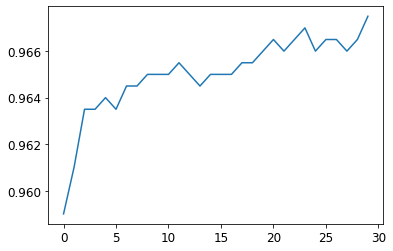

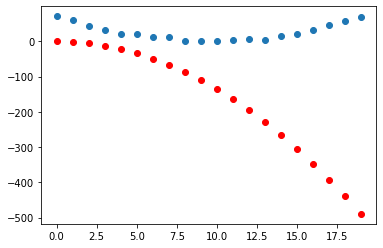
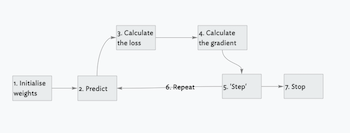
Some foundations for machine learning with PyTorch
I outline the basic process that a computer uses when training a model, greatly simplified and all explained through the lens of PyTorch and how it calculates gradients. These are some pre-requisite foundations that we will later apply to our Fashion MNIST dataset.
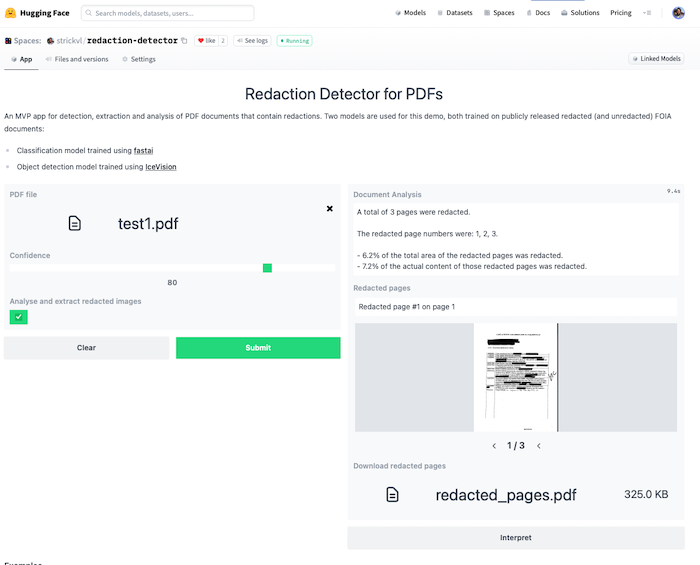
A painless way to create an MVP demo using computer vision models
I created a few deployed MVP demos showcasing models I’d created while participating in the fastai course, uploading them to the Huggingface Hub and using a Gradio Demo hosted on Huggingface Spaces.
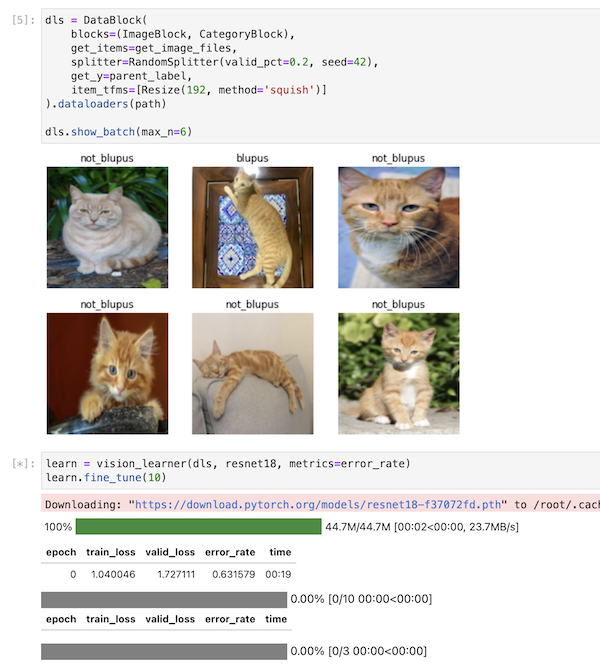
How my pet cat taught me a lesson about validation data for image classification
I learn a valuable lesson about how a model often will ‘cheat’ when training and sometimes the solution is a separate held-out set of ‘test’ data which can give a more accurate assessment of how well the model is performing.
![]()
How to trust the data you feed your model: alternative data validation solutions in a computer vision context (part 3)
In this third and final post on data validation for the computer vision context, I cover some alternative tools that you might want to consider, from Evidently to the humble ‘assert’ statement. I conclude by setting out some guidelines for when you might want to be doing data validation and which tools might be more or less appropriate for your specific problem.
![]()
How to trust the data you feed your model: data validation with Great Expectations in a computer vision context (part 2)
In this second post on data validation for the computer vision context, I show how you can use the automatic profiling feature of the Great Expectations library to get you started with increasing your confidence in your object detection annotations.
![]()
How to trust the data you feed your model: data validation with Great Expectations in a computer vision context (part 1)
An overview of the problem that data validation seeks to solve, explored through the lens of an object detection problem and some of the tradeoffs that such an approach might bring. I introduce and simplify the high-level concepts you need to use the Great Expectations library.
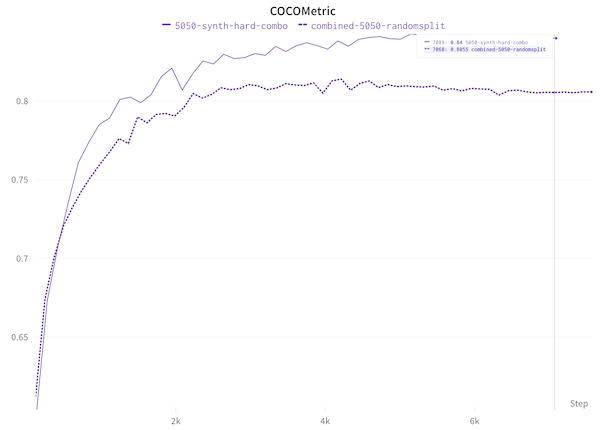
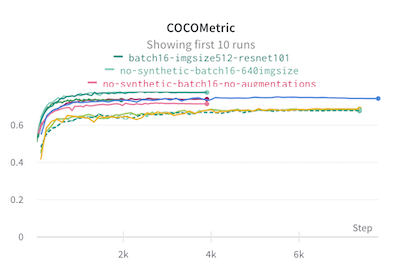
‘I guess this is what data-centric AI is!’: Performance boosts after training with synthetic data
I show how adding synthetic data has improved my redaction model’s performance. Once I trained with the synthetic images added, I realised a more targeted approach would do even better.


Starting Docker In A Month Of Lunches
I’m reading Elton Stoneman’s ‘Learn Docker in a Month of Lunches’ and blogging as I learn along the way. In chapters 1-3 we learn about the context for Docker as well as some basic commands for running and building containers.
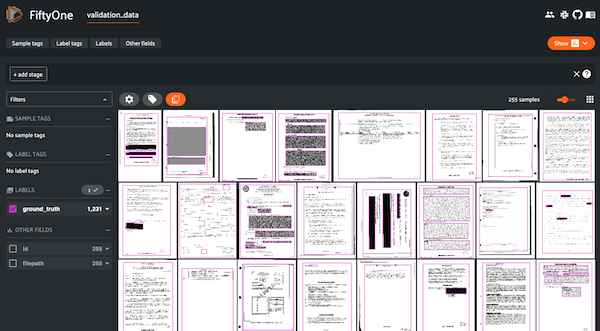
Figuring out why my object detection model is underperforming with FiftyOne, a great tool you probably haven’t heard of
I used the under-appreciated tool FiftyOne to analyse the ways that my object detection model is underperforming. For computer vision problems, it’s really useful to have visual debugging aids and FiftyOne is a well-documented and solid tool to help with that.

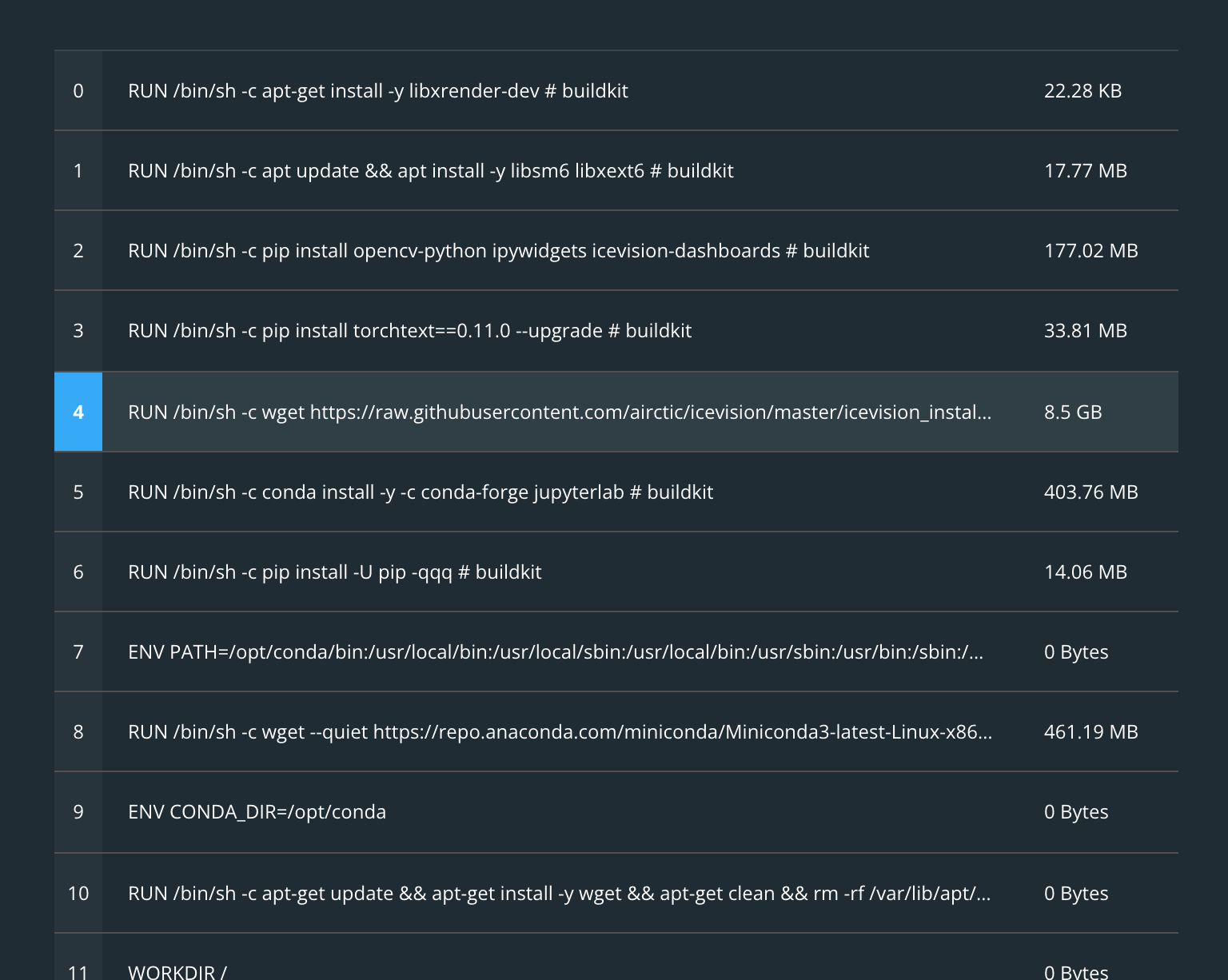
It’s raining bboxes: how I wrote a Python script to create 2097 synthetic images to help improve my machine learning model
I iterated through several prototypes to get to a script that could autogenerate synthetic training data for my computer vision model. I hoped to bootstrap my training to get a bit jump in model performance.

What are invariants and how can they help make your Python classes more robust?
Chapter 10 covers the last of the user-defined types explored in ‘Robust Python’: classes. We learn what an ‘invariant’ is and how to decide whether to use a data class or a class when rolling your own types.
Upgrade your Python dicts with data classes
Chapter 9 of ‘Robust Python’ dives into the uses of data classes, a user-defined datatype in which you can store heterogenous data together. They help formalise implicit concepts within your code and as a result also improve code readability.
Using mypy for Python type checking
Reflections on the sixth and seventh chapters of Patrick Viafore’s book, ‘Robust Python’. We slowly wind down our discussion of type hints in Python code and think through using mypy and how to introduce type hints to a legacy codebase.

Different ways to constrain types in Python
Reflections on the fourth chapter of Patrick Viafore’s recent book, ‘Robust Python’. We learn about the different options for combining types and constraining exactly which sets of types are permitted for a particular function or variable signature.

Learning about ‘nbdev’ while building a Python package for PDF machine learning datasets
Some early thoughts on the benefits and possible drawbacks of using fastai’s ‘nbdev’ literate programming tool which is a suite of tools that allows you to Python software packages from Jupyter notebooks.
Getting practical with type annotations and mypy
Reflections on the third chapter of Patrick Viafore’s recent book, ‘Robust Python’. We get some quick practical examples of how to use type annotation and how to use tools like mypy to analyse how typed values pass through your code.

What makes code robust?
Reflections on the first chapter of Patrick Viafore’s recent book, ‘Robust Python’.


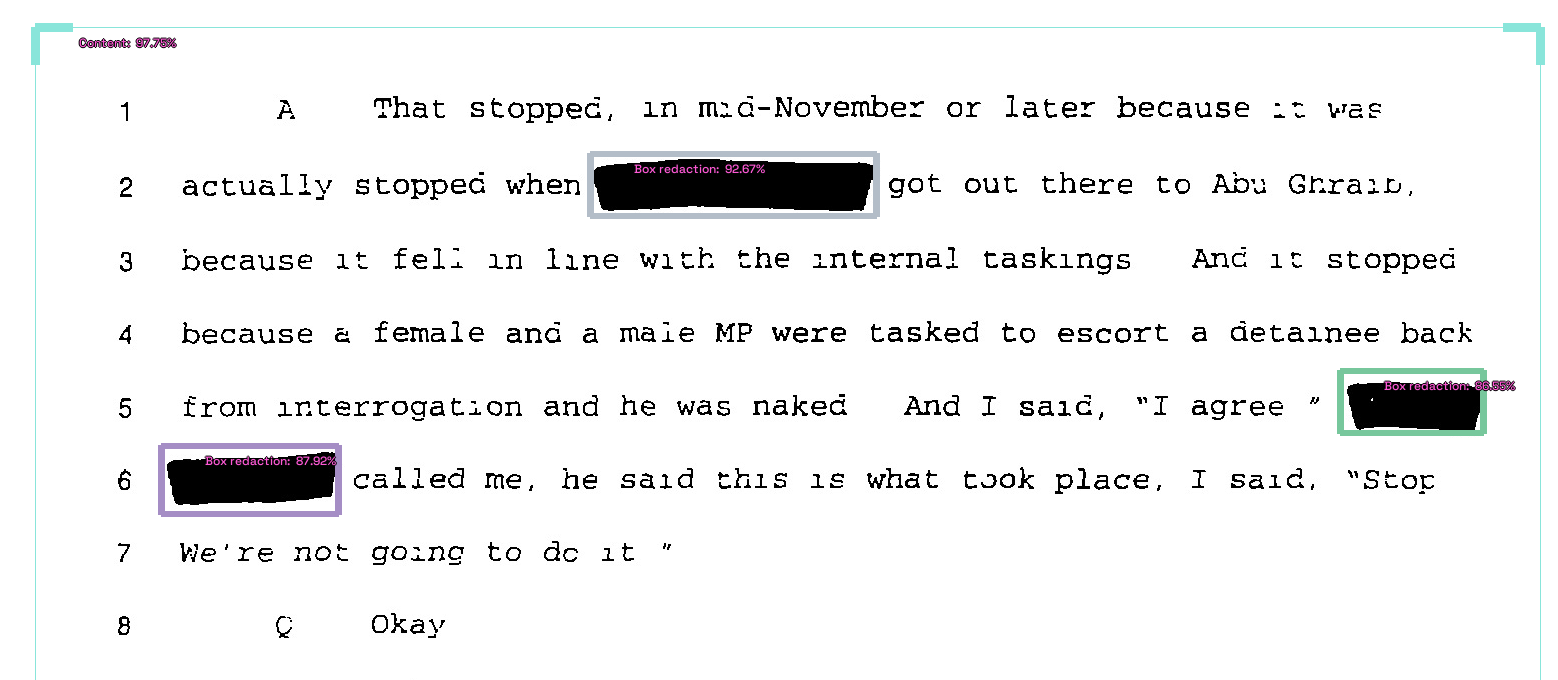
73% accuracy for redaction object detection
I made some progress on my redaction model.
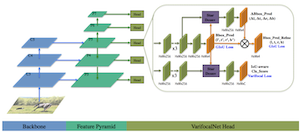
What is VFNet?
Some basics I learned about the object detection model vfnet.
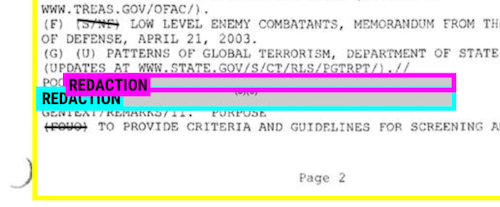
How to annotate image data for object detection with Prodigy
How I used Prodigy to annotate my data ahead of training an object detection model

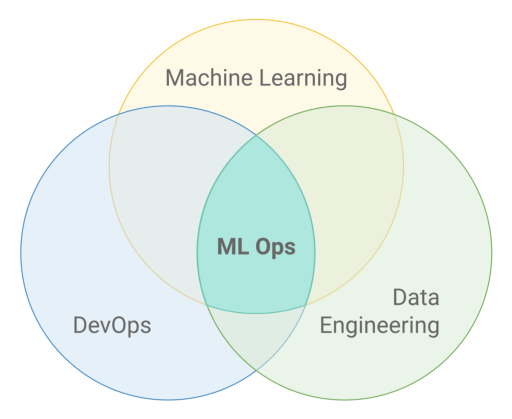
Launching a podcast about MLOps
I will be co-hosting a new podcast about MLOps called Pipeline Conversations.

![]()
Six problems TFX was trying to solve in 2017
I extracted the core problems that TensorFlow Extended (TFX) was looking to solve from its 2017 public launch paper.

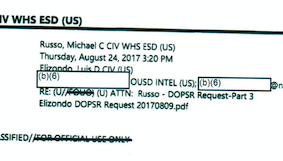
Training a classifier to detect redacted documents with fastai
How I trained a model to detect redactions in FOIA requests, using Prodigy for data labelling and the fastai library for model training