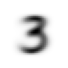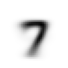tensor([[ 0, 0, 0, 0, 0, 0, 0, 42, 118, 219, 166],
[ 0, 0, 0, 0, 0, 0, 103, 242, 254, 254, 254],
[ 0, 0, 0, 0, 0, 0, 18, 232, 254, 254, 254],
[ 0, 0, 0, 0, 0, 0, 0, 104, 244, 254, 224],
[ 0, 0, 0, 0, 0, 0, 0, 0, 207, 254, 210],
[ 0, 0, 0, 0, 0, 0, 0, 0, 84, 206, 254],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 24, 209],
[ 0, 0, 0, 0, 0, 0, 0, 0, 91, 137, 253],
[ 0, 0, 0, 0, 0, 0, 40, 214, 250, 254, 254],
[ 0, 0, 0, 0, 0, 0, 81, 247, 254, 254, 254],
[ 0, 0, 0, 0, 0, 0, 0, 110, 246, 254, 254]], dtype=torch.uint8)